5G-LENA and LENA performance optimizations
Performance optimizations for LENA and 5G-LENA for nr-v3.1 and ns-3.42
Performance optimizations for LENA and 5G-LENA for nr-v3.1 and ns-3.42
Hi all,
We are pleased to announce that many performance optimizations have been made to the codebases that will be released as the 5G-LENA v3.1 and as the ns-3.42.
These performance optimizations are important for the new full MIMO model introduced in nr-v3.0, allowing for greater scalability of complex simulations.
The three primary optimizations are: reducing the sincos computations in the 3GPP propagation loss model, reducing the number of complex operations in the 3GPP propagation loss model, and a new fast codebook search algorithm for MIMO CQI feedback.
The first two optimizations also impact SISO scenarios, such as the lte-lena-comparison-user campaign, so we are going to see their results first.
Precompute and reuse sincos until the channel model (conditions) change
The channel model contains analog beamforming and channel condition information that changes when eNB/gNB and UE move relative to each other and over time.
However, the delay of ray clusters and angle between the position of receiving/transmitting antennas could be cached until the channel conditions saved, skipping expensive sincos computations.
These computations were performed over and over inside the last five nested loops of ThreeGppSpectrumPropagationLossModel::GenSpectrumChannelMatrix(), that unnecessarily recalculated the sincos for every combination of port. Note: there are actually four loops inside GenSpectrumChannelMatrix, but this call is repeated for every receiver.
This was done in two separate merge requests already merged to ns-3: MR1427 and MR1894.
Reduce complex operations in the 3GPP propagation loss model
The same nested loops at the end of ThreeGppSpectrumPropagationLossModel::GenSpectrumChannelMatrix() that used to recalculate sincos frequently, remains one of the most expensive parts of the simulation.
This cost relates to complex multiplications performed inside the five nested loops, scaling the computational complexity with the number of receivers, the number of receiver ports, number of transmitting ports, number of sub-bands and number of ray clusters.
By precomputing the product of the Doppler term and the cached delay sincos outside of this primary callsite, which is independent of the number of ports, we eliminate half of the multiplications performed in these nested loops.
This was done in a merge request already merged to ns-3: MR1888
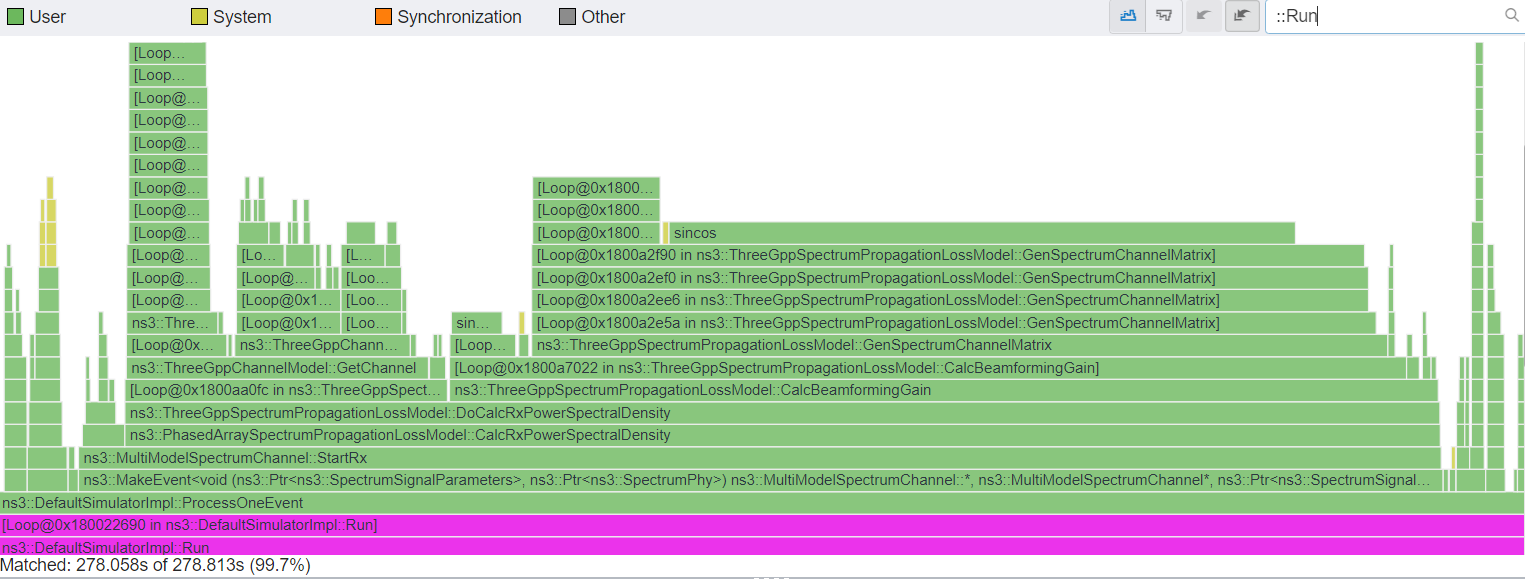
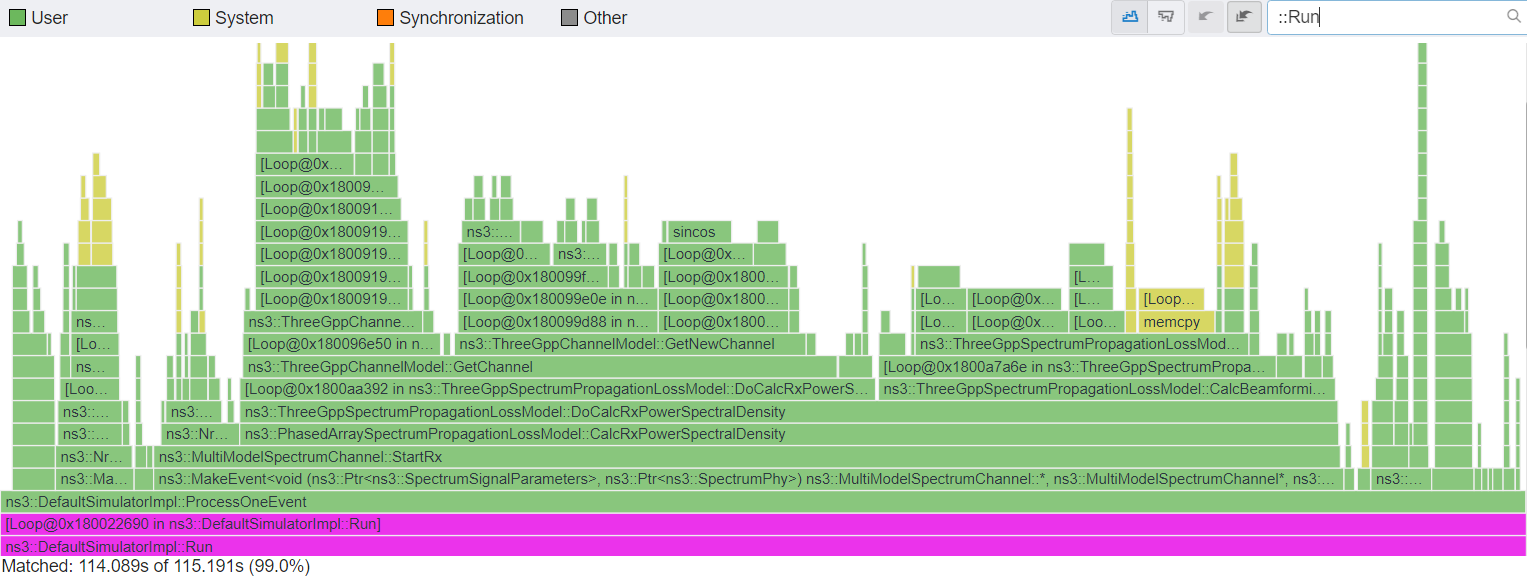
The three merge requests MR1427, 1888, 1894 combined result in a 1.93x speedup for lte-lena-comparison-user with the settings specified in MR1427. With all the other patches, we see a total speedup of 2.4x (278->115 seconds), as shown in the figures below.
Before optimization patches, as of ns-3.41 and nr-v3.0, total simulation time of 278 seconds
After optimization patches, which will be part of ns-3.42 and nr-v3.1, total simulation time of 115 seconds
Fast codebook search for MIMO CQI feedback
The NrPmFullSearch provides the exhaustive codebook search for the rank indicador (RI) and precoding matrix indicator (PMI) used for MIMO CQI feedback.
For our fast search, in MR137, we first separated the rank from the PMI search, then separated the wideband PMI (I1) from the sub-band PMI search (I2).
By cutting the search space at every step, we managed to get the CQI feedback 16x faster in large unrealistic scenarios with 32 ports on gNB and UE.
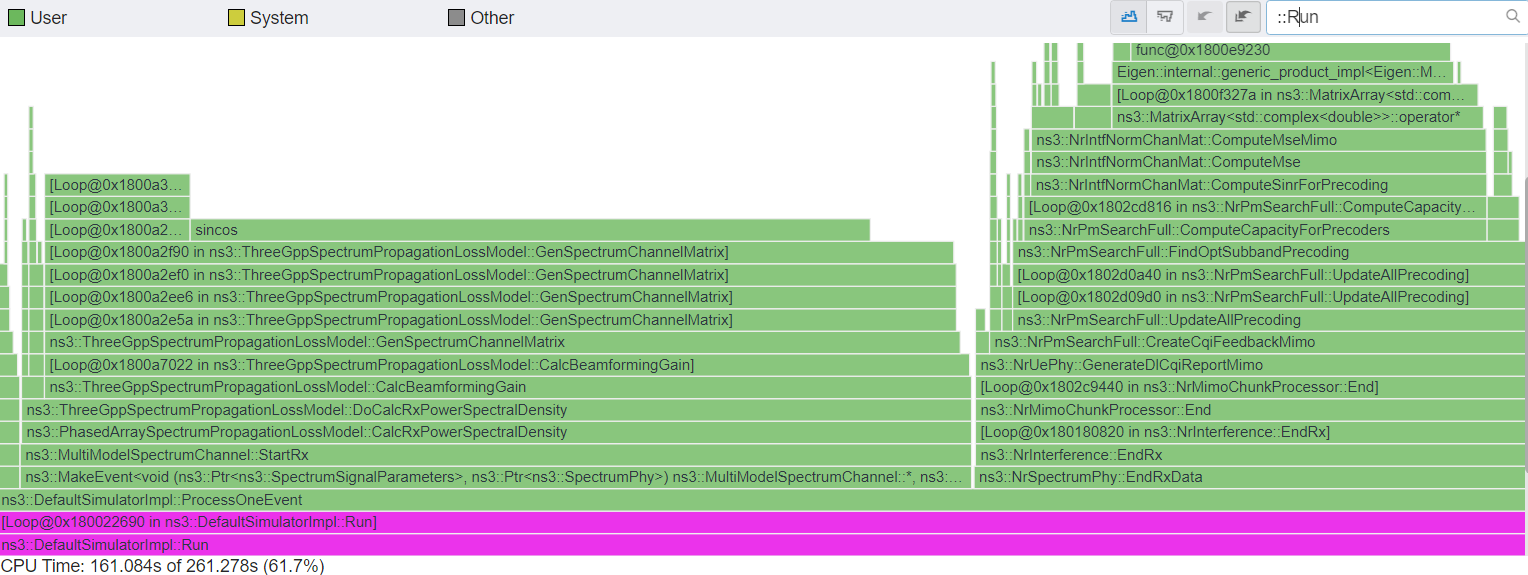
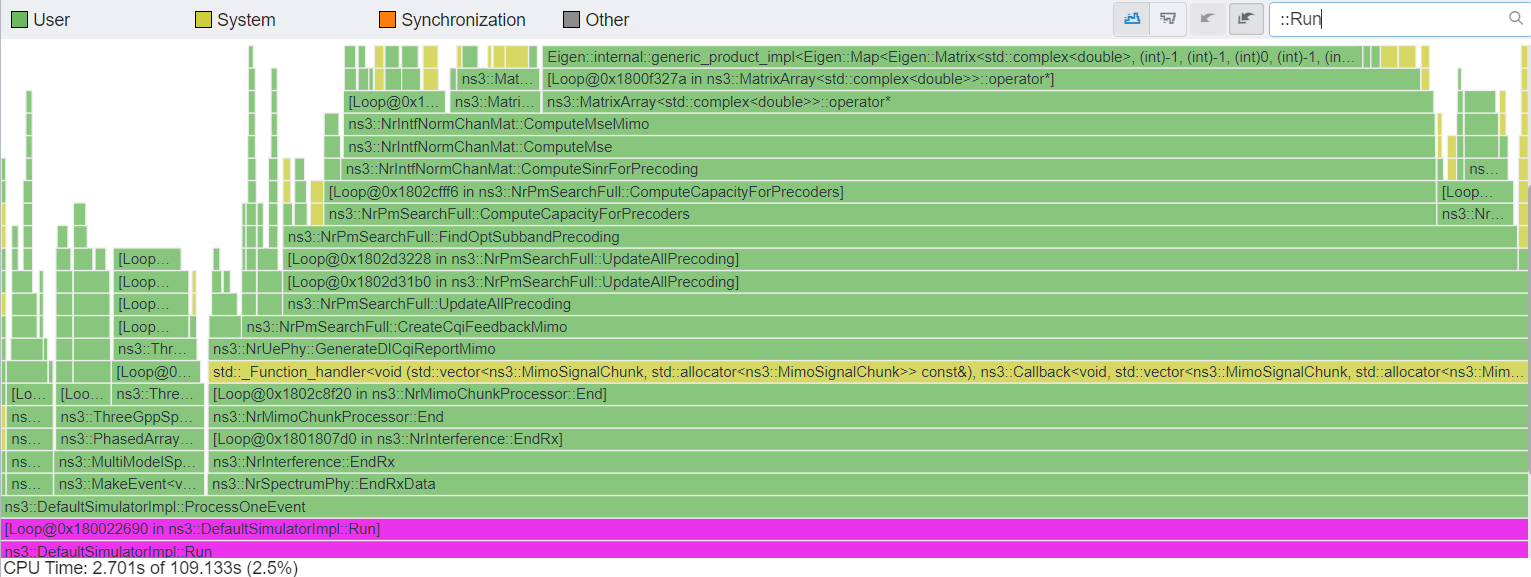
After applying all other optimization patches, cttc-nr-mimo-demo with the following parameters had an 11.8x total speedup (261->21 seconds).
cttc-nr-mimo-demo --numColumnsGnb=32 --numRowsGnb=2 --numHPortsGnb=8 --numVPortsGnb=2 --xPolGnb=1 --numColumnsUe=8 --numRowsUe=2 --numHPortsUe=8 --numVPortsUe=2 --xPolUe=1 --gnbUeDistance=300 --enableMimoFeedback=1 --fullSearchCb="ns3::NrCbTypeOneSp" --rankLimit=4
Before optimization patches, as of ns-3.41 and nr-v3.0, total simulation time of 261 seconds using --pmSearchMethod=ns3::NrPmFullSearch
After optimization patches, which will be part of ns-3.42 and nr-v3.1, total simulation time of 109 seconds using --pmSearchMethod=ns3::NrPmFullSearch
After optimization patches, which will be part of ns-3.42 and nr-v3.1, total simulation time of 21 seconds using --pmSearchMethod=ns3::NrPmFastSearch
Other optimizations
Unnecessary copies and memory allocations, incorrect container types, unnecessary processing of what should be constexpr, etc. We found a few of these during optimization work and fixed them.
These impact primarily smaller scenarios, where this expensive propagation and MIMO operations are not that frequent.
More information about the optimizations and their respective patches can be found in the table below. Speedups listed below are for cttc-nr-mimo-demo using its default settings.
| Project | MR | Description | Speedup |
|---|---|---|---|
| ns-3 | 1846 | Switch LteRlcUm::m_txBuffer container from vector to deque for O(1) front removal | 1.1x |
| ns-3 | 1847 | Reuse the Mac48Address static broadcast address instead of recreating everytime | 1.04x |
| nr | 111 | Use custom fast implementation of the exp() function | 1.32x |
| nr | 113 | Keep MAC scheduling trace files open throughout the simulation | 1.16x |
| nr | 114 | Prevent unnecessary malloc and copy of a lookup table in NrEesmErrorModel | 1.15x |
We are excited about the next release, with more realistic models and reasonable runtimes.
The 5G-LENA team