Hi all, We are happy to announce the v5.0 release of 5G-LENA. This release is compatible with ns-3.48. This release ships with an important heads-up for FDD users. We tracked down a bug in the 3GPP spectrum model that, under NLOS conditions, could make UEs receive up to 30 dB less power than they should. After applying the fix we measured up to a 1.4x reduction in the number of corrupted uplink transport blocks. TDD … Read more…
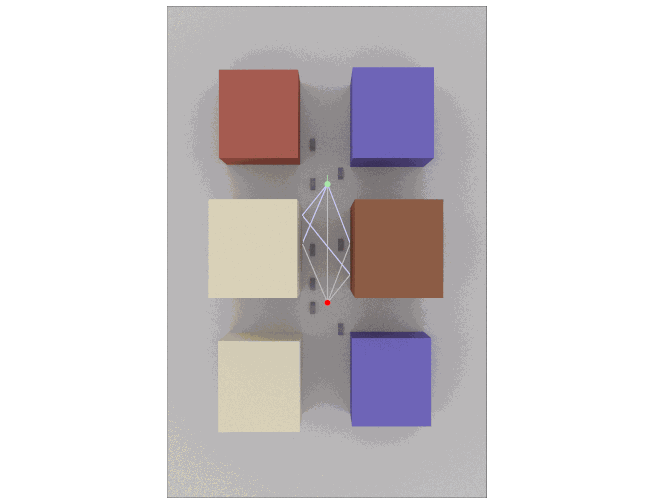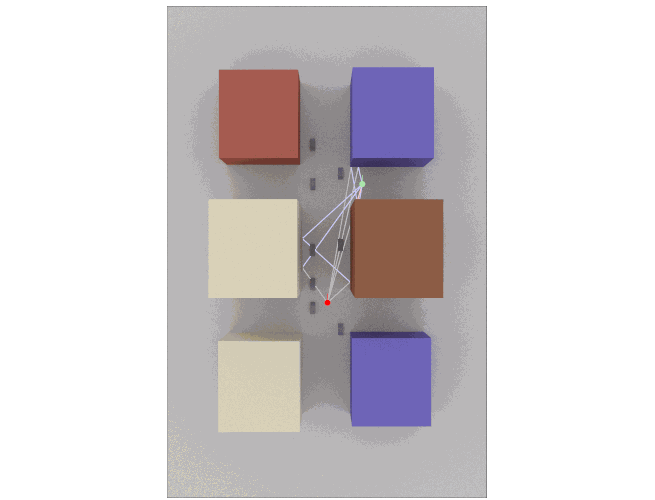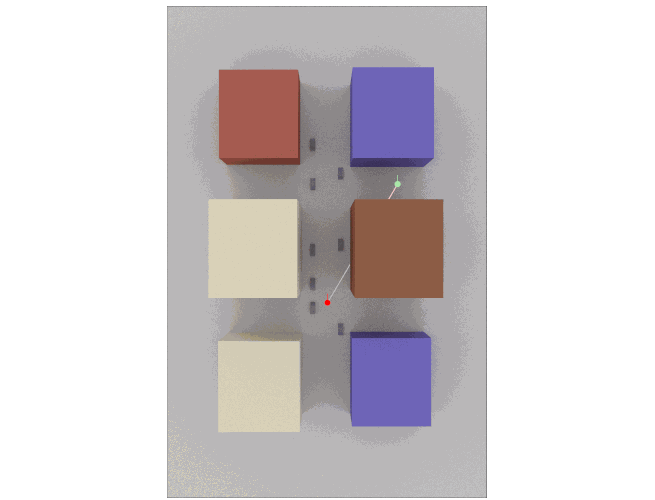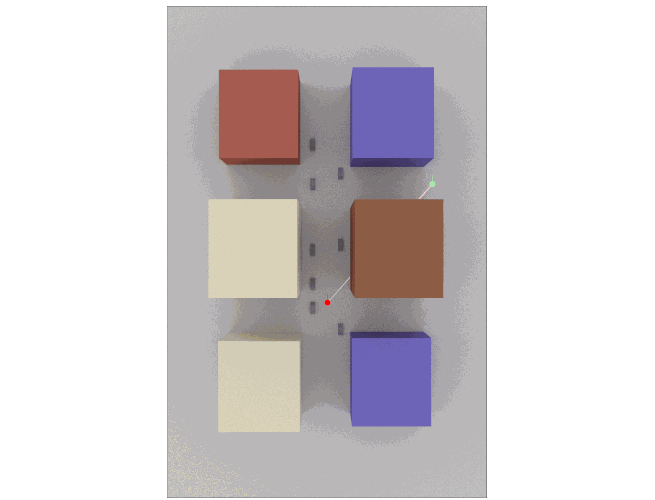
Wireless network simulation is only as meaningful as the realism of the channel model. As mobile nodes move - whether for pedestrian devices, vehicles, or drones - the channel between transmitter and receiver evolves continuously: multipath clusters shift, angles and delays change gradually, line-of-sight can break, shadowing varies. A model that “jumps” randomly at each update does not reflect reality and can … Read more…
Traditional channel models used in system-level simulations rely on analytic or stochastic approximations such as 3GPP TR 38.901. While efficient, they cannot accurately capture site-specific propagation, complex indoor/outdoor geometries, or interactions with dynamically placed objects. Sionna RT, on the other hand: We are excited to announce a new integration of NVIDIA Sionna RT, a real-time differentiable … Read more…
Hi all, Since the 5G-LENA repository (https://gitlab.com/cttc-lena/nr) is fully public, we have set the expiration date for all Guest members to November 2025. These Guest accounts were inherited from the period when the repository was private. We recently noticed that Guest members actually had more restricted access than any other user (e.g., they could not create merge requests), and this is why we have done such … Read more…
Hi all, We are happy to announce the v4.1 release of 5G-LENA. This release is compatible with ns-3.45. This release includes some features, such as: - Resource assignment matrix (currently used to ensure there are no overlapping allocated resources): - Wraparound model and support for hexagonal deployments, which allows for higher interference without requiring the simulation of additional rings, which can … Read more…
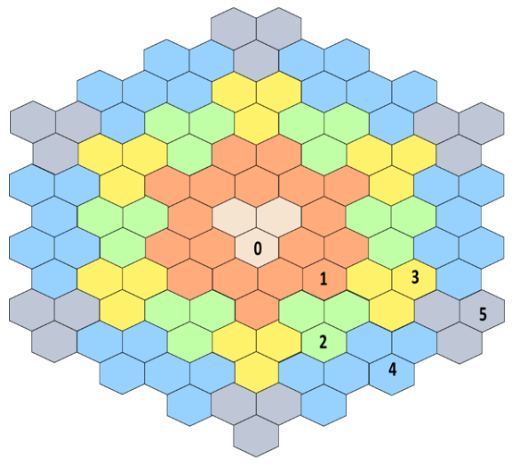
Lately, we’ve seen this trend of balancing two (seemingly opposite) goals from a network simulator performance perspective: We’re currently integrating a wraparound model into 5G-LENA, based on this publication: R. S. Panwar and K. M. Sivalingam, Implementation of wrap around mechanism for system level simulation of LTE cellular networks in NS3, 2017 IEEE 18th International Symposium on A World of Wireless, Mobile … Read more…
Hi all, We are happy to announce the v4.0 release of 5G-LENA. This release is compatible with ns-3.44. We would like to thank all 5G-LENA users who contribute continuously to the 5G-LENA community by opening issues, proposing solutions, and answering on 5G-LENA users list. Thank you for your support! To cite this NR 4.0 5G-LENA release please use: https://zenodo.org/records/15422217 (in addition to the reference … Read more…
Hi all, We are pleased to announce that a new release of the NR V2X extension of 5G-LENA simulator is available to download (v1.1). The main upgrade is the alignment of the module with the recently published NR v3.1 release, and several minor bugs were fixed. To download and configure the code, please follow the instructions in the README.md file … Read more…
Hi all, We are pleased to announce that 5G-LENA v3.1 is now available for download. This release is compatible with the latest ns-3.42, so the code base is updated for C++ conformance and aligned with ns-3.42. This release comes with two new features: 1) a completely new PMI Type-I Single Panel codebook for MIMO, supporting up to 32 antenna ports and 4 streams (rank 4) per user, and 2) the support of sub-band … Read more…
Hi all, We are pleased to announce that a new release of the NR V2X extension of 5G-LENA simulator is available to download (v1.0). The main upgrade is the alignment of the module with ns-3.42 and the current development version of nr. The main improvements are the addition of feedback-based HARQ (previously, only blind retransmissions were supported), and a more flexible sample scheduler that can handle multiple … Read more…
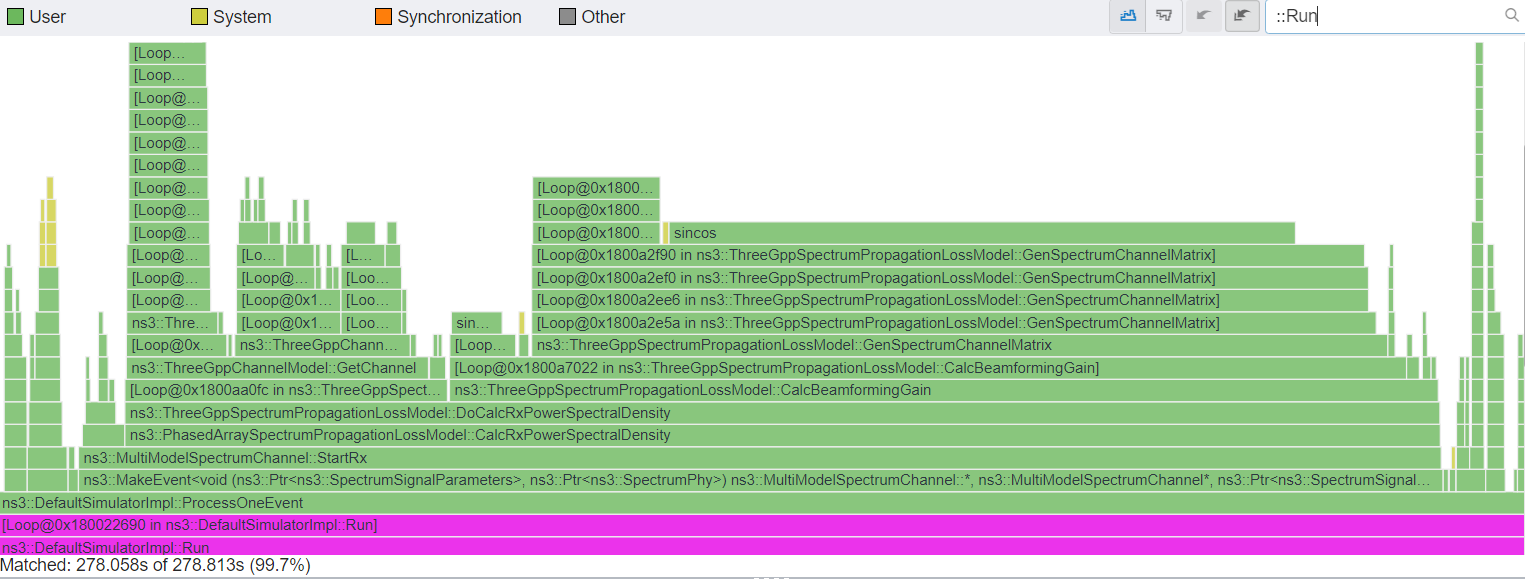
Hi all, We are pleased to announce that many performance optimizations have been made to the codebases that will be released as the 5G-LENA v3.1 and as the ns-3.42. These performance optimizations are important for the new full MIMO model introduced in nr-v3.0, allowing for greater scalability of complex simulations. The three primary optimizations are: reducing the sincos computations in the 3GPP propagation loss … Read more…
Hi all, We are pleased to announce that 5G-LENA v3.0 is now available for download. This release is compatible with the latest ns-3.41. One of the most important additions to this release is the support of a completely new full MIMO model. Comparing to the previous dual-polarized implementation, this new model offers a much more general approach and can be easily extended to support different types of MIMO, which … Read more…
We are pleased to announce that a new release of the NR V2X extension of 5G-LENA simulator is available to download (v0.3). The main upgrade is the alignment of the module with ns-3.40 and nr-v2.6. Also, it includes some fixes (e.g., it fixes a sensing bug in NrUeMac), a validity check for nr parameters (T1, T2, numerology, and reservation period), SfnSf expansion to prevent rollover, among others. To download and … Read more…
We are pleased to announce that 5G-LENA v2.6 is now available for download. This release is compatible with the latest ns-3.40. One of the most important additions to this release is the NR tutorial created by Giovanni Grieco in the scope of the GSoC 2023 project “IUNS-3 5G NR: Improving the Usability of ns-3’s 5G NR Module” mentored by Tom Henderson, Katerina Koutlia, and Biljana Bojovic. The main objective of this … Read more…
We are pleased to announce that 5G-LENA v2.5 is now available for download. This release is compatible with the latest ns-3.39. Some of the most important features of the 5G-LENA v2.5 include new QoS MAC schedulers, new design for the Logical Channel bytes assignment, including a new algorithm based on the QoS requirements of the flows, support of Release 18 5QIs and support of delay-critical GBR resource type. All … Read more…
We are pleased to announce that 5G-LENA v2.4 is now available for download. This release is compatible with the latest ns-3.38. Some of the most important features of the 5G-LENA v2.4 include a new traffic generator framework that allows to simulate NGMN traffic applications for mixed traffic scenarios and advanced and multi-flow 3GPP XR traffic applications, such as Virtual Reality (VR), Augmented Reality (AR), and … Read more…
We are pleased to announce that 5G-LENA v2.3 is now available for download. This release is compatible with the latest ns-3-37. Some of the most important features of the 5G-LENA v2.3 include the update of the module to the clang format (including clang-tidy), a new example scenario used for the calibration of the 5G-LENA under 3GPP reference scenarios, new traces, RSRP measurements, and some bug fixes. All the … Read more…
We are pleased to announce that 5G-LENA is now calibrated in 3GPP references scenarios. Following you can find a link of our paper: https://doi.org/10.1016/j.simpat.2022.102580 Also, it is available in open-access mode here: https://arxiv.org/abs/2205.03278 We are working to provide the next release with the calibration scenario as soon as possible, so stay tuned! The 5G-LENA team Read more…
We are pleased to announce that in 21th April 2022 and 6th May 2022 we released to the public the releases 2.0 and 2.1 of 5G-LENA NR module, respectively. Release v2.0 comes with a key new feature: Dual-Polarized MIMO (DP-MIMO). The current NR DP-MIMO model exploits dual-polarized antennas and their orthogonality to send the two data streams, by exploiting polarization diversity. The model does not rely on … Read more…
It is our great pleasure to announce that we have just released for public access the NR V2X extension of our 5G-LENA simulator. The basis of the NR V2X code departs from the NR 5G-LENA, and gets inspiration from parts of NIST D2D code (https://apps.nsnam.org/app/publicsafetylte/). It includes support of NR frame structure, PSCCH and PSSCH multiplexing, resource allocation for NR V2X using mode 2 (autonomous … Read more…
We are pleased to inform you that we got three papers accepted for publication and presentation in the Workshop on ns-3, taking place June 21-24 (virtual event). The details of the papers are as follows: We would like to use this occasion to thank all of you which have requested the access to the software, and are daily working to improve it through issues reports, feedback, and patches proposals. The 5G-LENA Team Read more…
We are pleased to announce that today, 7 June 2021, we are releasing to the public the release 1.2 of 5G-LENA NR module. This release contains FTP traffic model and important fixes. The list of new features, functionalities and hot fixes is reported in the release notes here (we documented each change in detail in the file CHANGES.md), and includes: FTP traffic model (model 1) and helpers, new APIs to compute SRS … Read more…
We are pleased to announce that today, 2 March 2021, we are releasing to the public the release 1.1 of 5G-LENA NR module. This release contains exciting features and bugs fixings. The list of new features and functionalities is reported in the release notes here (we documented each change in detail in the file CHANGES.md), and includes: uplink Power Control, NR-compliant Sounding Referece Signals (SRSs), realistic … Read more…
We are pleased to announce that today, 16 September 2020, we are releasing to the public the release 1.0 of our NR module. This release contains exciting features and bugs fixed. The list of new features and functionalities is reported in the release notes here (we documented each change in detail in the file CHANGES.md), and includes, among others exciting things, heterogeneous multi-cell configurations, FDD, new … Read more…
As of today, we opened a general, free, open google group for user discussion about 5G-LENA. It can be reached here: https://groups.google.com/g/5g-lena-users Feel free to participate! 5G-LENA team Read more…
It is with great pleasure that we release for public access the NR-U Channel Access Manager for our 5G-LENA product. The classes are modelling different ways to access the shared channel in unlicensed bands. We have a duty-cycle class (nr-on-off-access-manager.cc), and different Listen-Before-Access classes (nr-lbt-access-manager.cc). The implementations follow an existing interface in the NR module, so no updates … Read more…
We would like to let all know that development of the 5G-LENA simulator is active and we are working on new and exciting features. For example, we have NR-U for coexistence with WiGig in 60 GHz, LTE remodelling inside 5G-LENA, new multicell configuration helper to configure independently each eNB/gNB in the scenario (technology, band, numerology, BWP), and a new Radio Enviromental Map helper. Plus, we are working on … Read more…
5G-LENA v0.4 We have just released to the public a new version of the 5G-LENA software. This release includes the complete PHY abstraction model for error modelling in NR, compliant with the latest NR specification. For more details about the developed model, you can have a look at our paper, which has been accepted for presentation at the IEEE Int. Commun. Conf. (ICC). Here you can find the release notes (we … Read more…
We are glad to announce that the CTTC has received a grant from NIST (U.S. Commerce Department’s National Institute of Standards and Technology) call 2019-NIST-MSE-1 for a collaboration, entitled “Modeling, Simulation and Performance Evaluation of NR V2X”, to enable and accelerate New Radio (NR) Vehicular to Everything (V2X) communications, with special emphasis on Public Safety research. The proposal is focused on … Read more…
We are glad to announce that our overview paper entitled “New Radio Beam-based Access to Unlicensed Spectrum: Design Challenges and Solutions” has been accepted for publication by the prestigious IEEE Communications Surveys & Tutorials. You can access the preprint version of our paper under the “Early Access” area on IEEEXplore, by clicking here. Please remember to cite it in your publications, if your work is … Read more…
5G-LENA v0.3 We are pleased to announce that today, 28 August 2019, we are releasing to the public the second version of the 5G-LENA software. This release contains tons of fixed bugs, plus some exciting features. Worth mentioning is an updated channel model, with a separate procedure for beamforming and the possibility to compute UE/UE and gNB/gNB interferences. The code has been refactored to include a new MAC/PHY … Read more…
Hello everyone, we are pleased to inform you that our initial submission for 5G-LENA has been accepted for publication by the prestigious journal Simulation Modelling Practice and Theory, published by Elsevier. You can access the paper from this link. Please remember to cite it in your publications, if your work is based on ours: @article{5GLENA, title = {{A}n {E2E} simulator for {5G} {NR} networks}, journal = … Read more…
The official launch of 5G-LENA is here! 5G-LENA is a novel 5G NR network simulator, licensed under the GPLv2, that allows getting indicators from PHY to application layer from an end-to-end simulation of a 5G deployment. We designed it as a pluggable module for the widely known network simulator ns-3. The simulator is the natural evolution of LENA, the LTE/EPC Network Simulator, which was entirely designed and … Read more…
BARCELONA, Spain, Feb. 1, 2019 – The Centre Tecnològic de Telecomunicacions de Catalunya (CTTC) and InterDigital, Inc. (NASDAQ: IDCC), a mobile technology research and development company, have expanded their joint research efforts to advance the next generation of wireless technology. CTTC and InterDigital are developing solutions for 5G cellular technologies (including NR, MulteFire) and Wi-Fi/WiGig to cooperate … Read more…
Hello everyone, this is our first blog post. We hope that you will find the website as useful as possible. Since the Christmas vacation are really close, we wish you a wonderful time with your family, or with your chosen ones, and a really funny new year. Stay tuned! Read more…